[네트워크] Ch1 - 인터넷과 프로토콜, network edge
[네트워크] Ch2 - 네트워크의 원리 및 Application Layer
✨ 2.2.2 Cookies & Web Caching
📌 User-Server state: cookies
많은 웹 사이트들은 서버 사이드에서 클라이언트에 대한 history를 유지하기 위해 cookies를 사용한다.
앞서 프로토콜 자체는 stateless하다고 했는데, PCO가 줄어든다는 장점이 있지만 state를 기억함으로써 얻을 수 있는 많은 이점을 놓칠 수밖에 없다. stateless한 프로토콜의 단점을 극복하기 위해 서버 사이드에서는 쿠키를 사용하여 클라이언트에 대한 히스토리를 유지한다.
✅ Four components
- 서버 측에서 response message의 cookie header line을 보내준다
- 다음 HTTP request message에서 쿠키 헤더 라인을 보낸다.
- 쿠키 파일은 유저의 호스트(클라이언트)에 유지되고, 유저의 브라우저에 의해 관리된다.
- 웹 사이트(서버)에서는 유저의 정보가 백엔드 데이터베이스에 유지된다.
⁉️ example
수잔이라는 사람이 특정 PC에서 인터넷에 접근한다고 가정하자.
수잔이 처음으로 특정 e-commerce 사이트에 접속하면, 맨 첫 HTTP request에서 site는 다음의 요소들을 만든다.
- unique ID : 유저에 특화적인 ID를 부여한다.
- ID에 대한 백엔드 데이터베이스에 진입한다 : 다음 진입 시 ID에 대한 데이터에 진입할 수 있다.
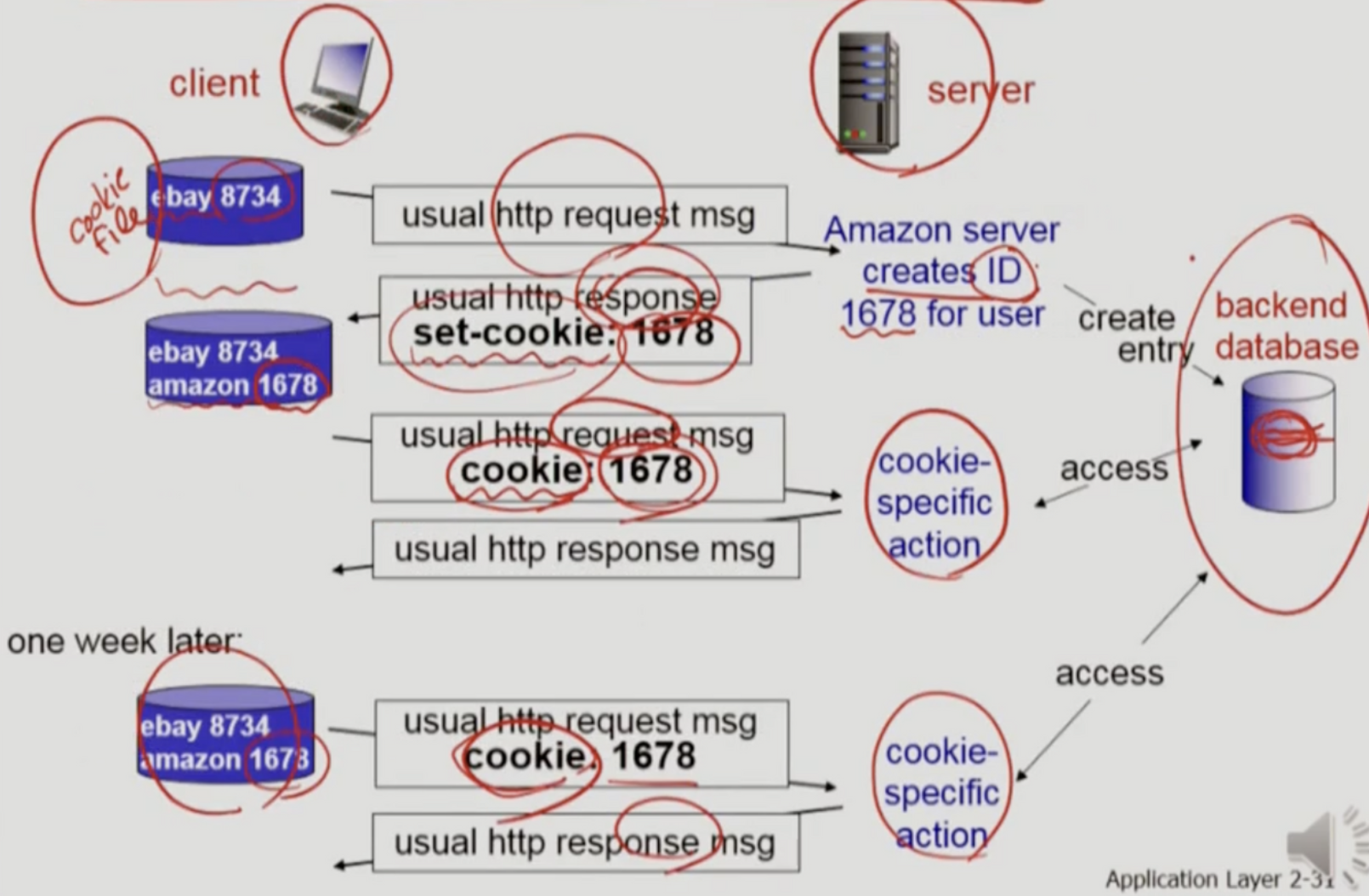
위 그림과 같이 클라이언트에는 쿠키 파일이 있는데, 이 쿠키에는 웹사이트가 알려준 아이디가 저장되어 있다.
- 어느날 이 사람이 아마존에 접속하고, request를 날린다고 생각해보자. 아마존은 이것이 최초 접속이라는 것을 인식하고, 새로운 ID를 만들어서 서버의 backend database에 저장하여 ID에 대한 entry를 형성하게 된다.
- 이후 response message에 ID를 실어서 보낸다. 이 ID는 header line에 set-cookie라는 필드를 만들어서 key-value 형식으로 보내진다. 그러면 클라이언트는 쿠키 파일에 아마존에서 받아온 ID를 저장해둔다.
- 그러면 다음에 접속했을 때에는 쿠키 파일에 있는 ID를 찾아서 헤더 라인에 cookie라는 필드의 값으로 보내준다.
- 이제 서버는 cookie-specific한 action을 할 수 있게 되어, 다시 이 유저에 맞는 정보를 보내준다.
- 일주일 뒤에 이 사람이 다시 아마존에 접속해도 쿠키 파일을 찾아서 자신의 ID를 보내준다.
📌 쿠키를 통해 할 수 있는 일
- authorization
- 웹 메일의 경우, 웹 메일의 사이트에서 계정에 로그인을 해야 한다. 원래는 아이디와 패스워드를 요구하여 post 메서드를 사용해서 정보를 사이트에 보낸다. 그러면 아이디를 verify해서 로그인을 시켜주고, 그 http session은 끝이 난다.
- 만약 다음에 이메일을 보고 싶다면 다시 로그인해야 하는데, 쿠키를 이용한다면 웹 사이트에서 현재 로그인된 상태라는 것을 저장할 수 있다. 그러면 authorization 없이도 웹 메일에 접근할 수 있다.
- shopping carts
- e-commerce 사이트에서 쇼핑 카트를 항상 유지하는 것도, 백엔드 사이트에 ID가 저장되어 있기 때문이다.
- recommendations
- user session state (Web e-mail)
Cookie와 privacy : 쿠키는 사이트가 유저에 대해 학습할 수 있게 해준다. 이 과정에서 privacy를 지키는 일이 중요하다.
state를 유지하는 방법 : protocol endpoints를 이용한다면 multiple transactions에 대해 sender와 receiver에서 상태를 항상 유지하고 있어야 하는 반면, cookie를 사용하면 메시지에 상태를 담아서 유지할 수 있다.
📌 Web caches ( proxy server )
1️⃣ Web Cache의 개념

목적 : 캐시를 로컬 사이트에 둬서 original 서버에 가지 않고도 object를 가지고 올 수 있게 한다.
유저의 브라우저는 캐시를 통해서 Web access하도록 세팅을 해놓는다.
브라우저는 모든 http request를 cache에다가 요청하게 된다.
- 만약 오브젝트가 캐쉬 안에 있으면 캐쉬가 object를 반환해주고
- 오브젝트가 캐쉬 안에 없다면 캐시가 origin server에 다시 요청을 보내고, 이를 다시 클라이언트에 보낸다.
웹 캐시를 다른 이름으로 proxy server라고 부르는데, 캐시가 마치 서버같은 역할을 하기 때문에 이렇게 부른다.
한 클라이언트가 proxy server에 리퀘스트를 보내고, 여기에 정보가 없다면 proxy server가 origin server에 요청을 보낸다. 이러면 proxy server에 object 정보가 저장되는데, 이 상태에서 다른 클라이언트가 동일한 요청을 보내면 proxy server에서 정보를 보내주게 된다.
2️⃣ 웹 캐시는 클라이언트인 동시에 서버이다
client의 original requesting을 받는 server의 역할
origin server에 대한 client 역할
3️⃣ 웹 캐싱을 하는 이유는?
- 일반적으로 cache는 ISP에 설치되어 있다(대학, 회사, residential ISP)
- 액세스 링크는 ISP에서 사기 때문에 트래픽이 늘어난다면 커질수록 ISP에 많은 돈을 내야한다. 그런데 web cache가 존재한다면 ISP로 왔다갔다하는 트래픽이 줄어들기 때문에 경제적으로 도움이 된다.
- 사용자 입장에서는 클라이언트의 request에 대한 response time을 줄여준다. core 쪽에 있는 서버보다 edge에 가까운 web cache의 속도가 빠를 수밖에 없기 때문이다.
- 웹 캐시가 인터넷의 edge 쪽에 풍성하게 분포되어 있기 때문에, 인터넷의 어느 한 귀퉁이에 있더라도 사용자들이 쉽게 접근할 수 있게 된다. 예를 들어 content providers의 자금이 넉넉지 않은 경우, 효율적으로 content를 전달할 수 있도록 해준다. 이는 P2P에서도 동일한 원리로 파일 공유를 쉽게 만들어준다.
4️⃣ Caching Example
윗부분이 Internet 부분이고, 아래쪽이 학교의 network라고 가정하자. 이 사이에는 access link가 존재하여 서로 연결된다. 문제 상황은 15.4 Mbps라는 access link의 대역폭이 평균적인 학교의 network 사용량의 감당하기 힘든 상황이라고 가정하자. 여기서 발생하는 Delay를 어떻게 해결할까?
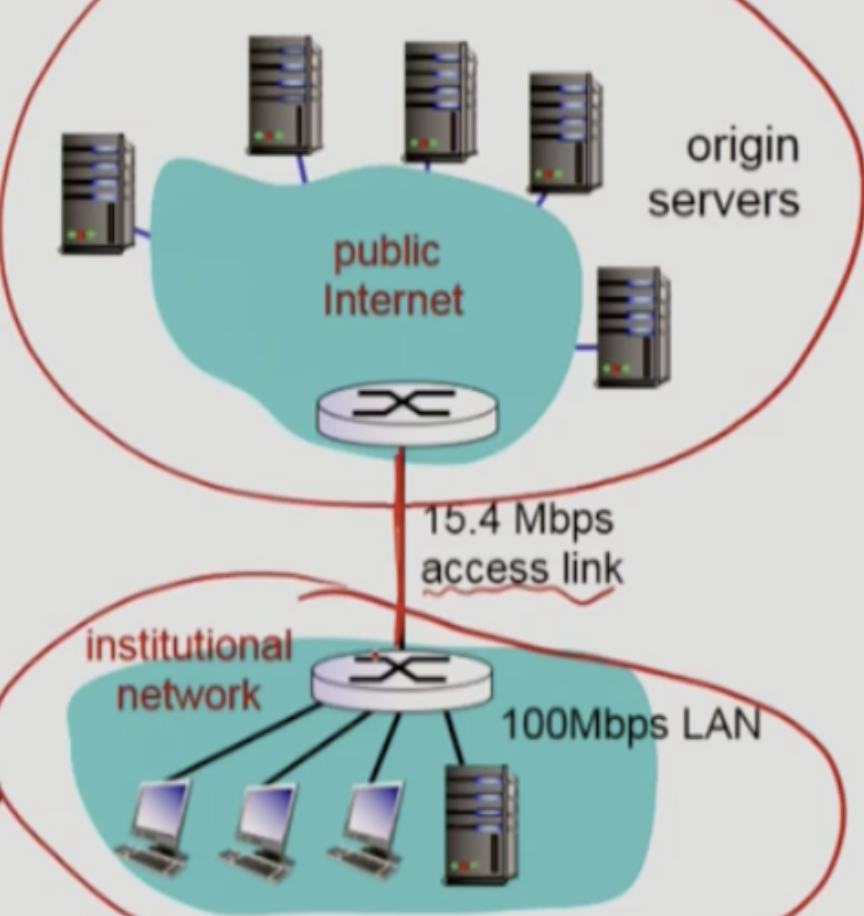
✳️ Access Link의 용량을 늘리는 방법으로 Delay를 해결하기
⁉️ 가정⁉️
- 평균 object size가 1M bits이다.
- 브라우저로부터 서버로 가는 평균 request rate는 15/sec이다.
- 그렇다면 브라우저로 가는 평균 데이터 전송 속도는 15Mbps이다.
- institutional router로부터 특정 origin server로 가는 RTT가 2초이다.
- access link rate는 15.4Mbps이다.
⁉️ 결론⁉️
→ 여기서 traffic intensity를 구하려면 데이터 전송 속도에서 access link rate(bandwidth)를 나눠주면 된다. 이것이 0.99로 거의 1에 가깝기 때문에 많은 딜레이가 생길 것이다.
→ LAN은 100Mbps이기 때문에 utilization(traffic intensity와 동의어)은 15%에 불과하지만 access link utilization이 99%인 굉장히 비효율적인 구조가 된다.
→ 전체 딜레이에 대한 계산식은 아래와 같다.
⭐ total delay = Internet delay + access delay + LAN delay = 2 sec + minutes + usecs
여기서 가장 큰 변인은 access에서 발생하는 delay이다. 랜의 속도가 아무리 빨라도 딜레이가 많이 발생한다.
⁉️ 해결⁉️
이를 해결하기 위해 access link를 10배 늘려서 154Mbps로 만들면, 전체 계산식은 internet delay인 2초 남짓한 시간만 걸리게 된다.
⁉️ 비용⁉️ : access link를 10배 늘렸기 때문에 ISP에 많은 돈을 지불해야 한다.

✳️ 다른 해결 방법 : Web caching을 이용하여 delay를 해결하기
Web cache를 하나 두게 되면, 특정 request는 ISP로 가야 하지만 local에서만 해결할 수 있는 request도 생기게 된다. 비용도 웹 캐시에 대한 구입 비용에 국한되어 저렴하게 된다.
⭐ Cache hit rate에 따라 access link utilization, delay를 계산하기
→ cache hit rate를 0.4로 생각하면, 40%의 request는 cache에 의해 수행되고, 60%의 request는 origin에 의해 수행된다.
→ 그러면 traffic intensity도 60%가 된다. ⇒ access link utilization : 60%
access link에서 브라우저에 대한 data rate를 계산하면 = 0.6 % 1.5Mbps = 9Mbps이다.
→ total delay
전체 딜레이의 계산식은 아래와 같다.
= 0.6 * (origin server로부터의 딜레이) + 0.4 * (cache로 request가 만족되었을 때의 딜레이)
= 0.6 * (2.01) + 0.4 (~msecs)
= ~ 1.2 secs
154Mbps link로 access link를 증설했을 때보다 빠른 동시에 가격도 싸다!
📌 Conditional GET
✳️ 필요성 : 캐시 서버가 오래된 data(즉, 잘못된 데이터)를 제공할 수 있는 위험성이 있다. 이를 Conditional Get이라는 방법으로 해결한다.
✳️ 목적 : 캐시가 최신 버전의 data를 가지고 있다면 server에서 object를 보내주지 않는 것 → server resource를 줄인다.
✳️ 방법
http request를 server에 보낼 때, header line에 If-modified-since라는 헤더에 date 값을 넣어서 보낸다. date를 기준으로 modify가 되지 않은 경우 : 이 date 정보는 서버에서 마지막으로 modify된 시간을 의미하고, 서버는 이 date를 기준으로 modify가 되지 않았다면 response를 보내되 object는 보내지 않는다. 부담을 최소화하는 것이다.
date를 기준으로 modify(update)가 된 경우 : 서버는 200 OK를 보내주면서 새로운 object를 보내준다.
이렇게 함으로써 web cache가 오래된 버전의 웹 페이지를 주는 것이 아니라 새로운 정보(올바른 정보)를 갱신할 수 있게 된다.
✳️ 한계
이러한 방법이 최신 버전을 보장할 수는 있지만, object를 보내지 않더라도 server와 통신하는 것은 동일하기에 항상 2초라는 딜레이가 유지되게 된다.
다른 방법으로 딜레이를 해결하기 위해 주기적으로 refresh를 시키는 웹도 있다. 가끔 refresh를 하지 않아도 새로운 페이지가 뜰 수 있는데, 페이지를 자주 modify하는 경우 웹 사이트에서 주기적으로 이를 갱신하는 것이다. 이러한 방법을 사용하는 경우 평균 딜레이는 이 갱신 간격을 짧게 할수록 길어진다. 물론 간격이 짧아지는 만큼 정보는 정확해질 것이다!
'CS > Network' 카테고리의 다른 글
| [네트워크] Ch2 - Web과 HTTP (0) | 2022.08.12 |
|---|---|
| [네트워크] Ch2 - 네트워크의 원리 및 Application Layer (0) | 2022.08.12 |
| [네트워크] Ch1 - Delay, loss, throughput in networks, Protocol layers, service models, Networks under attack: security, Internet history (0) | 2022.08.05 |
| [네트워크] Ch1 - 인터넷과 프로토콜, network edge (2) | 2022.03.23 |



